Allure Report Helper
AI RCA 架構解析
Python Flask 本機服務 + Azure OpenAI 多模態推論 + SQLite 稽核追蹤。
核心設計目標:分析結果可追溯、Vision Fallback 不中斷、批次 RCA 可監控。
一覽無遺,
全局盡在掌握。
為管理層與 SQA 打造的專屬戰情室,告別繁瑣的日誌比對,用直覺的介面秒懂自動化測試的每一處死角。

30 秒看懂這個技術頁
- Role: QA Automation Engineer / AI Tool Builder
- Problem: 失敗分析若只靠人工閱讀報告、截圖與日誌,批次 triage 速度與可追溯性都不足。
- Built: 本機 Flask 服務,整合 Allure parsing、多模態 RCA、fallback 策略與 SQLite 稽核資料庫。
- Stack: Python, Flask, Azure OpenAI Vision, SQLite, Teams summary flow。
- Result: 讓 AI 分析結果可監控、可回放、可複查,而不是只回傳一次性答案。
可信度與取捨
- What this demonstrates: 我不只會接 LLM API,也會設計 fallback、audit、history replay 與交付邊界。
- Project Status: Personal PoC / production-like prototype。
- Metrics Methodology: 指標來自個人 PoC、流程實測或專案觀測,用於說明改善幅度與評估方法;實際導入效益會依團隊規模、流程成熟度與系統限制而異。
- Evidence: 架構圖、hero 截圖、分析歷史、Teams 摘要與資料表設計。
- Source Access: 因涉及公司流程或資料限制,原始碼不公開;本頁提供架構圖、流程截圖與去識別化實作說明。
- Trade-offs: Vision 準確度依賴截圖品質與 UI 穩定性,且批次分析需要在成本與深度之間做配置。
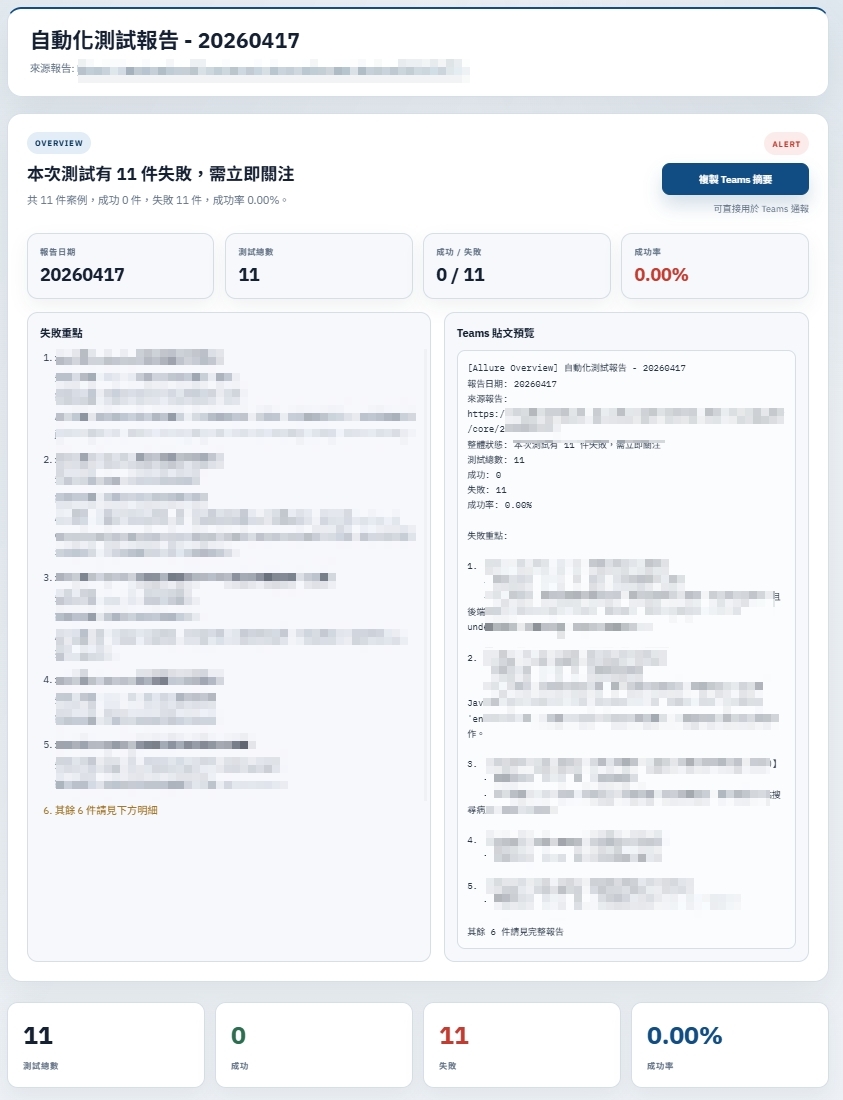
- 當 SQA 每天花超過 1 小時在「看失敗報告、整理摘要、廣播現況」這類例行勞動時。
- 當團隊想引入 AI 判斷,但又必須確保 AI 的每次呼叫都可被稽核、可追溯時。
- 截圖比對不只是視覺輔助——能讓模型從 UI 狀態差異中發現純文字日誌看不出來的線索。
- rule_only / fast / deep 三段分析策略解決了「需要速度 vs. 需要準確度」的取捨問題。
- SQLite 稽核 DB 是治理的核心,不只是 logging,它讓 AI 決策過程可被復現、可被審計。
Reflection:這套系統的邊界在哪裡?
在展開技術細節前,先說清楚這套系統能做什麼、不能做什麼,以及引入它的合理前提。
- 從 Allure 報告 URL 抓取失敗案例細節(step、trace、screenshot)
- AI 多模態 RCA(文字 + 前後截圖比對)
- 分析結果持久化與歷史載入
- 每次 AI 呼叫的完整稽核紀錄
- Teams 摘要一鍵複製
- 自動修改 automation 腳本(AI 只判斷,不動你的測試碼)
- 直接回寫 Allure 原始數據(唯讀取用)
- 測試排程與執行控制(那是 CI/CD 的責任)
- 需要已有能輸出 Allure format 的測試框架(Pytest / Playwright 等)
- AI 分析需要 Azure OpenAI 部署(rule_only 模式可純離線)
- 本機服務,無需部署到伺服器,但也因此不支援多人同時使用
手動翻查,
早該成為歷史。
對比傳統繁雜的操作流程,AI 自動化將你的注意力還給真正需要思考的決策點。
Tech Stack at a Glance
工程師最快掃描的地方:一張表看清楚各元件的技術選型。
| 元件 | 語言 / Runtime | 核心依賴 | AI 推論 | 狀態儲存 |
|---|---|---|---|---|
| main.py | Python 3.11 | Flask, http.server | — | 本機記憶體 |
| powerReporter.py | Python 3.11 | requests, Jinja2 | — | report_html/*.html |
| ai_analyzer.py | Python 3.11 | openai, rule_engine | gpt-4.1 / gpt-5-mini (Azure) | —(呼叫端保存) |
| audit_logger.py | Python 3.11 | sqlite3 | — | ai_call_audit.db |
| 前端報告頁 | Vanilla JS | Bootstrap 5, Prism.js | 呼叫 /analyze_trace API | analysis_history.json |
| rule_engine.py | Python 3.11 | json | —(純規則) | rules/common.json |
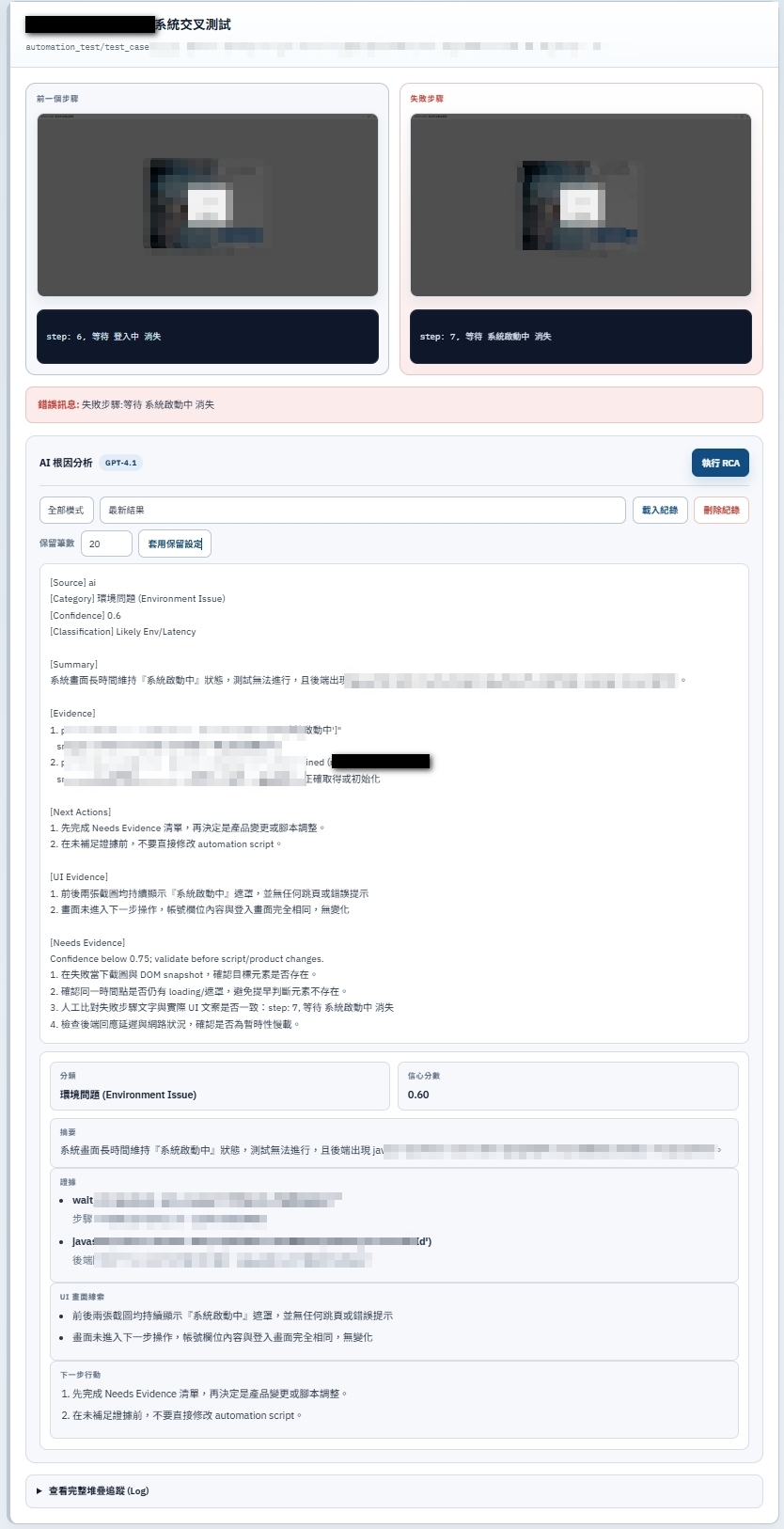
設計哲學:可追溯的 AI,而非黑盒子
關鍵設計決策:AI 每次呼叫都要有 audit trail,Vision Fallback 要對使用者透明,三段式分析策略解決速度 vs. 準確的取捨。
- AI 分析完直接顯示結果,無法知道它看了什麼
- 不知道是圖片送進去了還是純文字判斷
- 模型 Fallback 時用戶不知情,以為分析模型是自己選的那個
- 過去的分析結論無從復現,重跑就消失
- 每次 AI 呼叫寫入 SQLite,保存 prompt / payload / response
- 回傳 image_input_requested / image_input_used 明確區分
- Vision Fallback 在 UI 顯示 requested vs. effective model 差異
- analysis_history.json 持久化,跨次載入不丟失
{
"analysis": "根因分析結論(純文字)",
"structured": {
"category": "Timeout",
"summary": "元素等待超時,可能因網路延遲導致頁面未完全載入",
"confidence": 0.92,
"evidence": ["step 5 等待逾時 30s", "截圖顯示 loading spinner 仍在旋轉"],
"actions": ["增加等待時間", "確認測試環境穩定性"],
"ui_evidence": ["前一步截圖:頁面已渲染完成", "失敗步驟截圖:loading 覆蓋層仍可見"],
// — 模型透明度欄位 —
"requested_model_key": "gpt-5-mini",
"model_key": "gpt-4.1", // 實際使用(Fallback 後)
"image_input_requested": true, // 本次有截圖可用
"image_input_used": true, // 截圖確實送入模型
"vision_fallback_applied": true, // 因 gpt-5-mini 不支援 vision 而切換
"model_notice": "所選模型不支援圖片輸入,已自動切換為 gpt-4.1"
}
}優雅的架構,
串聯每一個環節。
從擷取、解析到推理,所有資料流暢通無阻,為企業級部署提供最堅實的後盾。
元件技術深潛
四個核心模組,各有技術亮點與選型理由。
rule_only 走規則引擎(毫秒級),fast 先做 triage 篩選再 RCA(減少深度呼叫),deep 直接全量推理含截圖。模型能力透過 config/ai_models.json 的 request_capabilities 欄位管理,不硬編碼。
def _build_messages(prompt, system, screenshots, model_caps):
"""
若模型支援圖片輸入且有有效截圖 URL,
改用 text + image_url 的 multimodal content 格式。
"""
content = [{"type": "text", "text": prompt}]
if model_caps.get("supports_image_input") and screenshots:
for url in screenshots:
if url: # 跳過 None 或空字串
content.append({
"type": "image_url",
"image_url": {"url": url, "detail": "high"}
})
return [
{"role": "system", "content": system},
{"role": "user", "content": content}
]每次真正送到模型的呼叫都在這裡留下完整紀錄:prompt、request payload、response body、截圖 URL、case context、模型切換原因。triage + RCA 是兩筆獨立紀錄,共用同一個 request_id。
def log_ai_call(
request_id, source, phase, # 'triage' | 'rca'
status, # 'success' | 'http_error' | ...
mode, report_id, case_key, case_name,
requested_model_key, model_key, model_label,
system_prompt, user_content, request_payload_json,
response_body, response_content, error_message,
duration_ms, trace_length, image_input_count,
failed_step_screenshot=None, previous_step_screenshot=None
):
conn = _get_conn()
conn.execute(INSERT_SQL, (
datetime.utcnow().isoformat(),
request_id, source, phase, status, mode,
report_id, case_key, case_name,
requested_model_key, model_key, model_label,
system_prompt, user_content, request_payload_json,
response_body, response_content, error_message,
duration_ms, trace_length, image_input_count,
failed_step_screenshot, previous_step_screenshot
))
conn.commit()上方工作台負責報告搜尋、切換、批次 RCA 進度與 Teams 摘要同步;下方 iframe 載入實際報告 HTML。兩者透過 postMessage state bridge 保持狀態同步,不需重整頁面。
// Viewer shell 監聽報告頁 postMessage
window.addEventListener('message', (event) => {
if (event.data?.type !== 'REPORT_PAGE_STATE') return;
const { pendingCount, overviewText, batchProgress } = event.data;
// 同步 Teams 摘要預覽
if (overviewText) teamsPreview.textContent = overviewText;
// 更新批次 RCA 進度
if (batchProgress) updateBatchUI(batchProgress);
});從 Allure 報告 URL 讀取 suites.json,找出所有 FAILED status 的案例,再各自抓取 case JSON、trace 檔與截圖 URL。最後用 Jinja2 模板組裝成含 Overview 區塊的 HTML 報告。
def _fetch_failed_cases(base_url, suites_data):
"""遍歷 suites.json,找出 FAILED 案例並抓取細節。"""
failed = []
for suite in suites_data.get("children", []):
for case in suite.get("children", []):
if case.get("status") != "failed":
continue
uid = case.get("uid")
# 取得該案例的完整 JSON(含 steps、trace、attachments)
detail = requests.get(f"{base_url}/data/test-cases/{uid}.json",
timeout=15).json()
failed.append(_extract_case_info(detail, base_url))
return failedLessons Learned
四個真實遇到的問題,每個都讓架構調整了一次。
函式在 iframe 內呼叫時找不到
原本的做法:把 emitReportPageState() 定義在報告頁的一個 IIFE 內,避免汙染全域。
問題症狀:RCA 執行後,console 出現 emitReportPageState is not defined。透過 iframe 呼叫時,函式找不到正確的作用域。
修正:把 emitReportPageState 掛到 window 上,讓 iframe 和 postMessage 橋接程式碼都能直接存取,同時用 JSDoc 加上命名警告避免後續覆蓋。
選了 gpt-5-mini 但實際跑的是 gpt-4.1
原本的做法:Fallback 在後端靜默切換,只記 log,不回傳給前端。
問題症狀:使用者認為自己的成本控制策略(用便宜模型)有效,實際上每次都在跑更貴的模型。更嚴重的是,無從解釋分析結果為何比預期好或差。
修正:在 API response 加入 vision_fallback_applied、requested_model_key、model_key 與 model_notice,前端 UI 明確顯示「您選擇 X,實際使用 Y,原因是 Z」。
「失敗步驟」和「錯誤摘要」幾乎一樣
原本的做法:Teams 摘要把失敗步驟、錯誤摘要、AI 摘要三個欄位全部貼出來。
問題症狀:貼到 Teams 後訊息很長,「失敗步驟」和「錯誤摘要」的內容高度重複,讓讀者要一直跳著看。
修正:在 buildOverviewCopyText() 中先比對「失敗步驟」和「錯誤摘要」的相似度,若重複度高就省略錯誤摘要,只保留失敗步驟 + AI 摘要 + UI 線索,並以 【案例名稱】 + 空行格式分隔。
20 個案例跑到一半,UI 沒反應
原本的做法:批次 RCA 在後端串行跑,前端只顯示一個 spinner,等全部完成才更新。
問題症狀:案例多時,等待超過 5 分鐘,使用者不確定是程式掛了還是還在跑,會直接重整頁面導致批次中斷。
修正:改由 viewer shell 逐條呼叫 /analyze_trace(每完成一條等一秒),並在上方工作台即時顯示「完成數 / 成功數 / 失敗數 / 目前處理中的案例名稱」,讓使用者知道系統仍在運行,也可以在任一完成後的節點決定是否繼續等待。